.png)
Kalbotyra ISSN 1392-1517 eISSN 2029-8315
2025 (78) 36–62 DOI: https://doi.org/10.15388/Kalbotyra.2025.78.2
Marie Flüh
Institut für Germanistik
Fachbereich: Sprache, Literatur und Medien I
Universität Hamburg
Von-Melle-Park 6
20146 Hamburg, Deutschland
E-Mail: marie.flueh@uni-hamburg.de
ORCID iD: https://doi.org/0000-0002-1707-284X
https://ror.org/00g30e956
Abstract. Im Rahmen dieses Beitrags soll ein Lehrkonzept für die Professionalisierung angehender Lehrkräfte vorgestellt werden, dessen Schwerpunkt auf der Synchronisierung von digitalen Grundkompetenzen im Umgang mit Methoden der digitalen Textanalyse – wozu auch literaturwissenschaftlich ausgerichtete Korpusanalysen zählen – mit einer literaturdidaktischen Kompetenzentwicklung liegt. Nach einer kurzen terminologischen Verortung werden im ersten Teil des Beitrags Motivation und Relevanz für den Brückenschlag zwischen Digital Humanities und Lehrkräfteausbildung herausgestellt. Der zweite Teil fokussiert konzeptuelle Grundlagen, Wissensbereiche und den groben Verlauf des Seminars Digitale Literaturwissenschaft und Literaturdidaktik (durchgeführt im WiSe 23/24 und WiSe 2024/25 am Institut für Germanistik der Universität Hamburg, gefördert durch die Stiftung Innovation in der Hochschullehre) unter besonderer Berücksichtigung der Einheit zur Korpusanalyse. Abschließend werden Ergebnisse, Chancen und Grenzen des Lehrkonzepts beleuchtet.
Schlüsselwörter: Digital Humanities, Computational Literary Studies, Germanistik, Didaktik, Hochschullehre, Lehrkräfteausbildung
Abstract. This article presents a teaching concept for the professionalization of prospective teachers. The concept is focused on the synchronization of basic digital skills in dealing with different methods of computational text analysis – which also includes literary studies-oriented corpus analyses – with the development of didactic skills. After a brief introduction, the first part of the article highlights the motivation and relevance of bridging the gap between digital humanities and teacher training. The second part focuses on conceptual foundations, areas of knowledge, and the rough outline of the seminar “Digital Literary Studies and Literary Didactics” (held in the Winter semester of Study year 2023/24 and the Winter semester of 2024/25 at the Institute of German Studies at the University of Hamburg) with special consideration of the session on corpus analysis. Finally, the results, opportunities and limitations of the teaching concept are examined.
Keywords: digital humanities, computational literary studies, German language and literature, didactics, pedagogy, teacher training
_____________
Submitted: 04/04/2025. Accepted: 06/06/2025
Copyright © 2025 Marie Flüh. Published by Vilnius University Press
This is an Open Access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
1 Einleitung: Digitalität in der Schule und der Literaturwissenschaft
Mittlerweile hat die Digitalisierung Einzug in viele Bereiche des öffentlichen und privaten Lebens gehalten und beeinflusst die Praxis des Forschens, Lernens und Lehrens an Schulen sowie Hochschulen. Ausgehend von einer in den 1990er Jahren noch widersprüchlichen fachdidaktischen Debatte – entweder grundlegend ablehnend, distanziert-kritisch oder affirmativ verlaufend – ist das Verständnis des Computers als reines Schreibmedium längst ersetzt durch das Bewusstsein für dessen große Bedeutung als Informations- und Kommunikationsmedium und Forschungsinstrument (Albrecht 2014, 138 f.). Das Populärwerden von generativer Künstlicher Intelligenz (gKI) in Form von niedrigschwellig anwendbaren Tools wie Gemini oder ChatGPT hat die große Bedeutung und das Bewusstsein für den Einfluss, den die digitale Transformation auf Leben, Arbeiten sowie Bildungs- und Lernprozesse hat, weiter erhöht.
Warum ist ein Brückenschlag zwischen Digital Humanities (DH) und Didaktik bzw. Lehrkräfteausbildung sinnvoll? Dieser Frage soll vor allem im folgenden Abschnitt nachgegangen werden, bevor ein konkretes Lehrkonzept zur Brückenbildung zwischen den beiden Fachdisziplinen vorgestellt wird. Im Rahmen einer digitalisierungsbezogenen Bestandsaufnahme wird zunächst erläutert, welche Rolle die Digitalisierung im schulischen und im literaturwissenschaftlichen Kontext spielt. Dabei werden Leerstellen sichtbar, die sich – so argumentiere ich in diesem Beitrag – durch eine engere Verzahnung von Inhalten der digitalen Literaturwissenschaft und Lehrkräfteausbildung für das Unterrichtsfach Deutsch füllen lassen.
1.1 Digitalität und Schule
Dass technische Medien im Deutschunterricht einen Platz einnehmen sollten, ist eine Erkenntnis, die sich ausgehend vom didaktischen Diskurs der 1970er Jahre ihren Weg in den Schulunterricht gebahnt hat (Frederking & Krommer 2014, 150 f.).1 Im schulischen Bereich stehen Lehrkräfte in der Verantwortung, Schüler:innen zu einer reflektierten Teilhabe am Leben in einer digitalisierten Welt zu befähigen. Um eine verantwortungsvolle Teilhabe von Schüler:innen an einer digitalisierten Gesellschaft zu garantieren, ist es notwendig, die Lehrer:innen erst einmal selbst mit den entsprechenden Kompetenzen auszustatten. Im Rahmen der Strategie für „Bildung in der digitalen Welt“, einer Verordnung der Kultusministerkonferenz (KMK) der Länder, wird Medienerziehung als fächerübergreifendes Prinzip vorgestellt, das den verbindlichen Kompetenzerwerb in sechs Kompetenzbereichen („Suchen, Verarbeiten und Aufbewahren“, „Kommunizieren und Kooperieren“, „Produzieren und Präsentieren“, „Schützen und Agieren“, „Problemlösen und Handeln“, „Analysieren und Reflektieren“) in allen Unterrichtsfächern vorschreibt (KMK 2026, 16 f., 19). Trotzdem gelten vorzugsweise Deutsch, Kunst, Musik und Sozialkunde als Leitfächer der Medienerziehung (Lecke 2008, 49). In einer digital vernetzten Welt, in der die sogenannte „digitale Revolution“ in vollem Gange ist und ein großer Teil der Meinungsbildung in und mit digitalen Medien erfolgt (Tillmann 2017, 116), stellt sich daher die Frage, was der Literaturunterricht dazu beitragen kann, um die künftige Gesellschaft – in der nach Schrift, Sprache und Buchdruck vor allem digitale Medientechnologien eine zentrale Rolle spielen (Aßmann 2017, 137) – auf das Leben in dieser Welt vorzubereiten. In der zweiten Ausbildungsphase finden praktizierende Lehrkräfte unter anderem in schulinternen oder zentral angebotenen Fort- und Weiterbildungsmaßnahmen methodische und didaktische Unterstützung für den kompetenzorientierten Deutschunterricht mit digitaler Komponente. Im Rahmen der ersten Ausbildungsphase, dem Hochschulstudium, wird vor allem im Teilbereich der Mediendidaktik Grundlagenwissen über die Entwicklung, die Funktionsweise und die unterschiedlichen Einsatzmöglichkeiten von technischen Medien in Lehr-Lern-Szenarien vermittelt. Als Inspiration und Orientierungshilfe für Lehrer:innen in allen Ausbildungsphasen dienen Publikationen und praxisorientierte Handreichungen für Lehrkräfte zur Auseinandersetzung mit digitalen literalen Medien im Deutschunterricht.2 Durchgeplante Unterrichtseinheiten finden sich beispielsweise zum Einsatz didaktisch aufbereiteter Computerspiele, zu unterschiedlichen Formen medialen Präsentierens (zum Beispiel mit Textverarbeitungsprogrammen oder Präsentationstools) sowie zum Recherchieren und Kommunizieren im Internet. Der Einsatz von E-Books in Verbindung mit dem Zugriff auf Online-Enzyklopädien und anderen mediengebundenen Funktionen wird als Form der digitalen Auseinandersetzung mit Digitalisaten vorgestellt. Hierbei werden die inhaltliche Erschließung und ein wiederholendes Lernen durch das Markieren signifikanter Inhalte oder Schlüsselbegriffe begleitet (Brand 2015, 135 f.). Weitere didaktisch fundierte Ideen für den digitalen Deutschunterricht stellt auch der Sachbuchautor und Lehrer Philippe Wampfler vor. Sie bestehen in der Erarbeitung eigener Wikipedia Einträge, der Arbeit mit Google-Docs als kollaborative Form der Textarbeit, dem Umschreiben von literarischen Texten als E-Mail, SMS oder X-Roman, der Erarbeitung von Unterrichtsblogs oder dem Verfassen von Gedichten mittels Messengerdiensten (Wampfler 2017). Darüber hinaus ist im Zuge der Fördermaßnahmen des DigitalPakt Schule (2019–2024 und 2025–2030) neben dem Ausbau der technischen Infrastruktur auch eine länderübergreifende Infrastruktur zur Bereitstellung und Bewertung digitaler Bildungsmedien erarbeitet worden, auf die Lehrkräfte zurückgreifen können.3 Dazu gehören vor allem die offene und frei zugängliche Bildungsmediathek MUNDO, die lizenzrechtlich und qualitativ geprüfte Materialien für den Schulunterricht zur freien Verfügung stellt. Einen fortlaufend aktualisierten Überblick über Unterrichtsideen zur Auseinandersetzung mit digitalen literalen Medien im Deutschunterricht (und allen weiteren Unterrichtsfächern) bietet außerdem das Portal digital.learning.lab. Der kursorische Streifzug durch Publikationen zum digital-affinen Unterricht zeigt also eine Vielzahl an Angeboten und Unterrichtskonzepten für den Literaturunterricht. Eine Suchanfrage für die nach KMK-Kompetenzen gegliederten Angebote des digital.learning.lab zeigt allerdings, dass für den Kompetenzbereich „Problemlösen und Handeln“, der eine Auseinandersetzung mit Algorithmen vorsieht, nur wenige Ideen für den Literaturunterricht zur Verfügung stehen. Die Suchabfrage ergibt nur zwei Treffer. Auf der zentralen Plattform für Open Educational Resources (OER) MUNDO werden für Suchbegriffe wie „digitaler Literaturunterricht“, „digitale Textanalyse“ oder „Korpusanalyse“ gar keine Treffer angezeigt. Hinsichtlich des Einsatzes statistischer Verfahren im Umgang mit digitalen Texten im Deutschunterricht herrscht also eine gewisse Ratlosigkeit vor: „Da ihre Verfahren sowohl an die Programm- wie an die Deutungsseite hohe Anforderungen stellen, ist nicht auf Anhieb klar, wie diese Ansätze für die Schule fruchtbar gemacht werden können.“ (Wampfler 2017, 146) Ansätze aus dem Bereich Distant Reading im Schulunterricht sind selten zu finden. Überlegungen für eine erzähltheoretische Analyse von Kleists Marquise von O. mittels Suchfunktionen und Tag-Clouds (Wampfler 2017) oder die Analyse literarischer Texte mit dem Distant Reading-Tool Voyant (Kühnert 2017; Flüh 2024a [2019]) sind als Ausnahmen aufzufassen. Gleiches gilt für Unterrichtsideen zur Sentimentanalyse mit SentText (Urs 2021), zur manuellen digitalen Annotation mit dem Textanalysetool CATMA (Flüh 2024 [2020]) oder zur Netzwerkanalyse (Flüh 2024b [2019]). Bis hierhin kann also festgehalten werden, dass es ein breites Spektrum und vielseitige frei verfügbare Unterrichtsideen für den Einsatz digitaler Medien im Deutschunterricht gibt. Weder Distant-Reading-Verfahren noch digitale Close-Reading-Verfahren, wie digitale manuelle Annotation (s. Kapitel „Digitale Literaturwissenschaft und Didaktik“), haben bisher Einzug in den Deutschunterricht gefunden. Das mag vor allem daran liegen, dass neben den ohnehin involvierten Bezugswissenschaften Literaturwissenschaft und Literaturdidaktik auch die Informatik als nahezu völlig fremde beteiligte Komponente eine Rolle spielt.
1.2 Digitale Literaturwissenschaft und Didaktik
Im universitären Bereich haben sich die Digital Humanities (DH) als Fachbereich, Methodenrepertoire und Forschungsgemeinschaft herausgebildet. Trotz der andauernden Diskussion darüber, was genau die Digital Humanities nun sind (Sahle 2015), lässt sich festhalten, dass es sich um einen Wissenschaftsbereich handelt, in dem geisteswissenschaftliche Forschungsfragen computergestützt bearbeitet werden (Limpinsel 2016) und zwar bereits seit den späten 1940er Jahren: Als eine Art Gründungsmythos der DH gilt die Erstellung des „Corpus Thomisticum“, eines ersten digitalen Indexes der Werke Thomas von Aquins auf Lochkarten, die der Jesuitenpater Roberto Busa in Zusammenarbeit mit IBM entwickelte (Lauer 2013, 103 f.). Bis heute ist die Möglichkeit der statistischen Betrachtung von geisteswissenschaftlichen (in Busas Fall theologischen) Werken ein zentraler Arbeitsbereich der Digital Humanities. Ein weiterer Teilbereich der DH ist die digitale Literaturwissenschaft. Ein zentraler methodischer Schwerpunkt der Computational Literary Studies (CLS) sind Ansätze, die unter dem Begriff Distant Reading zusammengefasst werden können. Der von dem Literaturwissenschaftler Franco Moretti eingeführte Begriff (Moretti 2016) beschreibt heute Analysen, in denen mithilfe von Computern und statistischen Verfahren große Textmengen untersucht werden. Digitale Literaturanalysen, in denen Distant-Reading-Verfahren eingesetzt werden, machen oft methodische Anleihen bei der Computer- und Korpuslinguistik (Jannidis 2010, 109). Anders als beim Close Reading, also der genauen, textnahen, auf ausgewählte Texte begrenzten Lektüre, bilden bei vielen Distant-Reading-Verfahren große Textkorpora den Untersuchungsgegenstand. Der quantitative Zugriff auf Literatur zielt in der Regel darauf ab, Verteilungsmuster zu erkennen und auf diese Weise die Ergebnisse von Einzelfallstudien in einen breiteren Kontext zu setzen. Dabei lassen sich je nach Zusammensetzung des Textkorpus und der Methode bspw. stilistische Besonderheiten (Schumacher 2022), thematische Schwerpunktsetzungen (Weitin & Herget 2017), emotionale Trends (Kröncke et al. 2023), Aspekte von Intertextualität (Yang et al. 2024), Genderreferenzen (Schumacher & Flüh 2023) oder – in einer populärwissenschaftlichen Aufbereitung der CLS – Eigenschaften von zeitgenössischen Bestsellern (Archer & Jockers 2017) für ganze Epochen, Œuvres oder unterschiedliche Gattungen analysieren. Doch in welcher Verbindung steht die digitale Literaturwissenschaft zur Didaktik und ferner zur Ausbildung angehender Lehrkräfte? Seitens der digitalen Literaturwissenschaft gibt es zwar Überlegungen und Ansätze für die Hochschullehre (Hirsch 2015; das Hauptangebot der Online-Plattform forTEXT; Mischke, Trilcke & Sluyter-Gäthje 2022; Bläß et al. 2022; Battershill & Ross 2022; Risam 2019; Jackaki & Faull 2016; Mauro 2016; Mahony & Pierazzo 2015), der Transfer in den schulischen Bereich und eine mögliche Integration in die Ausbildung angehender Lehrkräfte werden bisher aber eher wenig berücksichtigt.
Unter Rückbezug auf die eingangs skizzierte Rolle der Digitalisierung im bildungspolitischen und schulischen Kontext zeigt sich auf der einen Seite die Forderung nach einem Deutschunterricht, der an den KMK-Kompetenzen orientiert ist und Schüler:innen zur reflektierten Teilhabe an der digitalisierten Welt befähigt. Darunter fallen im Teilbereich „Problemlösen und Handeln“ die Anforderungen, „Digitale Medien und Werkzeuge zum Lernen, Arbeiten und Problemlösen nutzen“ und „Algorithmen kennen und formulieren“ zu können (KMK 2016, 19). Konkrete Ideen für den Literaturunterricht, die diese Aspekte adressieren, sind rar. Der größte Sprung in Richtung einer praktischen Auseinandersetzung mit Algorithmen scheint nicht Ergebnis einer gezielten bildungspolitischen Entscheidung, sondern primär durch wirtschaftliche Entwicklungen motiviert zu sein; schließlich hat erst die Publikation des Chatbots ChatGPT durch das amerikanische Unternehmen OpenAI die Auseinandersetzung mit generativer Künstlicher Intelligenz gesamtgesellschaftlich beinahe unausweichlich gemacht. Das zeigt sich auch in der Stellungnahme der Ständigen Wissenschaftlichen Kommission der Kultusministerkonferenz (SWK 2024) zu Sprachmodellen und ihren Potenzialen im Bildungssystem. Darin vorgesehen sind unter anderem eine engere Zusammenarbeit zwischen Praxis und Wissenschaft zur Entwicklung fachspezifischer, altersgerechter Nutzungs- und Aufgabenszenarien. Das Positionspapier betont außerdem, dass Lehrende und Lernende eine umfassende Kompetenz zum lernförderlichen Umgang mit großen Sprachmodellen (Large Language Model/LLM) benötigen, die in allen Ausbildungsphasen vermittelt werden sollte. Während in der Grundschule und dem Beginn der Sekundarstufe I die Ausbildung von Lese- und Schreibkompetenzen im Vordergrund stehen, sollen im Laufe der Sekundarstufe I zunehmend auch digitale Tools zur Erstellung von Texten eingesetzt werden. Ab der achten Klasse – so das Positionspapier – ist der regelmäßige Einsatz von LLMs als Schreibunterstützung in allen schriftbasierten Fächern sinnvoll (SWK 2024, 18 f.). Im Hinblick auf den Umgang mit LLMs zeigt sich also eine technikbejahende Position, die ähnlich wie im Fall der KMK-Strategie aus dem Jahr 2016 eine Integration in den Schulunterricht vorsieht. Dafür müssen zunächst die Lehrkräfte lernen, wie Sprachmodelle funktionieren, für welche Aufgabenbereiche sie eingesetzt werden können und für welche nicht. Darüber hinaus bedarf es konkreter Szenarien für den Schulunterricht. Dass der regelmäßige Einsatz vor allem für die schriftbasierten Fächer vorgesehen wird, legt nahe, dass die Auseinandersetzung mit der Funktionsweise von Sprachmodellen angehende und praktizierende Deutschlehrer:innen in besonderem Maße betrifft.
Die digitale Literaturwissenschaft stellt ein umfangreiches, etabliertes und kritisch reflektiertes Methodenrepertoire zur digitalen Textanalyse bereit. Künstliche Intelligenz (KI) und große Sprachmodelle werden in den Geisteswissenschaften bereits seit den Anfängen von KI in den 1950er Jahren theoretisch perspektiviert und auch für literaturwissenschaftliche Fragestellungen eingesetzt (Cardoso et al. 2009; Shanahan & Clarke 2023). Eine Verbindung beider Bereiche ist eher als Ausnahmeerscheinung zu bewerten. Das im folgenden Teil vorgestellte Lehrkonzept verknüpft beide Bereiche: Schule, hier bezogen auf die Ausbildung angehender Lehrkräfte für das Fach Deutsch, und Digital Humanities, hier bezogen auf die Computational Literary Studies (CLS) als literaturwissenschaftlicher Teilbereich der Digital Humanities.
2 Konzeptuelle Säulen des Seminars „Digitale Literaturwissenschaft und pädagogische Praxis“
Data-Literacy-Education für angehende Deutschlehrer:innen wird in zwei konzeptuellen Säulen aufgegriffen, die an den Kompetenzen orientiert sind, die die Studierenden durch die Seminarteilnahme erwerben sollen (s. Abb. 1).
Abbildung 1. Zweisäuliges Konzept für das Seminar „Digitale Literaturwissenschaft und pädagogische Praxis“
2.1 Computational Literary Studies (CLS): Methodenkompetenz / grundständige Lehre: Vermittlung etablierter digitaler Verfahren und Methoden der Textanalyse
Im Bereich „CLS: Methodenkompetenz / grundständige Lehre“ werden drei Teilbereiche von Data Literacy angesprochen: 1. die Vermittlung von Fachwissen über Konzepte und Methoden der digitalen Literaturwissenschaft; 2. die Fähigkeit, diese anzuwenden und 3. die Reflexion über Chancen und Grenzen quantitativer Ansätze für die literaturwissenschaftliche Forschung. Der Fokus dieses Themenkomplexes liegt auf der praktischen Anwendung: Die Studierenden erwerben Methodenkompetenz im Umgang mit digitalen Verfahren der Textanalyse, indem diese mithilfe exemplarisch ausgewählter Tools selbst ausprobiert werden. Zu den wichtigsten unüberwachten Lernverfahren zählen beispielsweise digitale Stilometrie oder Topic Modeling. Verfahren des überwachten maschinellen Lernens werden in Form von Handwritten Text Recognition, Named Entity Recognition oder dem Modelltraining eines Classifiers zur automatischen Annotation von Genderrollen einbezogen.4 Ein weiterer Bestandteil sind digitale Varianten klassischer geisteswissenschaftlicher Methoden (beispielsweise digitale manuelle (kollaborative) Annotation oder digitale Netzwerkanalyse). Neben der praktischen Anwendung stellt die kritische Reflexion der Methoden und der damit erzeugten Daten einen wichtigen Bestandteil dar.
2.2 Didaktische Kompetenz und Beurteilungskompetenz: Rückkopplung an didaktische Konzepte und bildungspolitische Rahmenbedingungen
In diesem Teilbereich des Seminars werden zwei Aspekte von Data Literacy angesprochen: 1. die Vermittlung von Fachwissen über bestehende (medien)didaktische Konzepte als didaktisches Fundament für einen Literaturunterricht, in dem digitale Verfahren der Textdatenanalyse zum Einsatz kommen und 2. (da die Literaturdidaktik an diesem Punkt noch entwicklungsbedürftig ist) die Reflexion darüber, wie sich digitale Verfahren der Textanalyse auf bestehende didaktische Modelle auswirken und wie ein Transfer in den schulischen Bereich gestaltet werden kann. Zentral ist die Frage danach, welche Handlungsmöglichkeiten für den Literaturunterricht durch den Einsatz digitaler Verfahren der Textanalyse entstehen und wie Unterrichtskonzepte aussehen können, in denen unter Berücksichtigung des Primats der Pädagogik literarische Texte und Textkorpora digital analysiert werden. Zum didaktischen Grundstock zählen bspw. das TPACK- und das SAMR-Modell (Mishra & Koehler 2006; Zierer 2018; s. Kapitel „Verknüpfung von Wissen auf verschiedenen Ebenen“)5 und die Auseinandersetzung mit bildungspolitischen Rahmenbedingungen in Form der KMK-Kompetenzbereiche, ausgewählte Positionspapiere und bestehende Ressourcen für einen digitalen Deutschunterricht, die im Seminar unter Rückbezug auf die CLS-Perspektive diskutiert werden.
3 Zielgruppe und Transferkonzept
Das Lehrangebot richtet sich an Lehramtsstudierende für das Unterrichtsfach Deutsch in der Sekundarstufe II, die sich im Masterstudium befinden. In diesem Stadium ist davon auszugehen, dass auf literaturwissenschaftliche und didaktische Grundkenntnisse aufgebaut werden kann, die wichtig sind, um die digitalen Methoden in eine literaturwissenschaftliche / didaktische Traditionslinie einordnen und kritisch hinterfragen zu können. Zugleich erfordert das Lehrangebot keine technischen Vorkenntnisse oder Erfahrungen mit den Methoden der CLS. Die Sitzungen mit DH-Anteil ermöglichen einen niedrigschwelligen Einstieg. Auf diese Weise soll die Hemmschwelle abgebaut werden, technische und quantitative Verfahren in die Literaturanalyse und die Unterrichtsplanung einzubeziehen. Die im Seminar verwendeten Tools sind so ausgewählt, dass Sie Mindestbedingungen für den Einsatz im Schulunterricht erfüllen. Dazu zählen aus meiner Perspektive, dass die Tools möglichst kostenfrei und unter einer Open Source Lizenz abrufbar sind, eine hohe Benutzerfreundlichkeit aufweisen (also über eine grafische Benutzeroberfläche verfügen und intuitiv bedienbar sind) und eine transparente Datenverarbeitung und -speicherung gewährleisten.
Durch den Wissenstransfer zwischen Literaturdidaktik und digitaler Literaturwissenschaft sowie die Synchronisierung von digitalen literaturwissenschaftlichen Grundkompetenzen mit einer fachspezifischen, didaktischen Kompetenzentwicklung erbringt das Seminar entscheidende Transferleistungen. Während die Studierenden im Seminar einen Grundstock an etablierten Verfahren und Tools kennenlernen, ist es im Rahmen einer nachhaltigen Professionalisierung wichtig, sie auch über den universitären Kontext hinaus dazu zu befähigen, aus dem breiten Spektrum an Tools und Methoden eigenständig eine fundierte sowie lerngruppenorientierte Auswahl treffen und beurteilen zu können, welche Analyseverfahren / Tools sich für den Einsatz im Schulunterricht eignen und welche nicht. Das Seminar soll diese Transferleistung unterstützen, indem ein Grundverständnis für die Funktionsweisen, die Chancen und die Grenzen quantitativer Verfahren der Textanalyse vermittelt und eine erste Annäherung an darauf abgestimmte Unterrichtskonzepte unternommen wird. Transfer ist außerdem als Brückenschlag zwischen etablierten Bezugswissenschaften (nicht-digitale Literaturwissenschaft / Literatur- und Mediendidaktik) und neuen Bezugswissenschaften (digitale Literaturwissenschaft / Literatur- und Mediendidaktik) gedacht. Leitend ist dabei die dem zweisäuligen Seminarkonzept zugrundeliegende und im Seminar stetig verhandelte Frage, wie bestehende didaktische Konzepte und Ansätze der CLS zusammenpassen. Der Aufbau und die Vernetzung von fachlichem, pädagogischem und technologischem Wissen bildet eine wichtige Grundlage für einen Literaturunterricht, der Technologien nicht isoliert betrachtet, sondern Inhalte der Literaturdidaktik und Verfahren der DH sinnvoll kombiniert und durch eine didaktisch fundierte Integration digitaler Methoden in den Literaturunterricht einen verstehensorientierten Zugang zu und Umgang mit Daten vermittelt. Das Handwerkszeug dazu sollte im Rahmen des hier beantragten Lehrkonzepts erarbeitet, ausprobiert, evaluiert und für Dritte bereitgestellt werden.
4 Verknüpfung von Wissen auf unterschiedlichen Ebenen
Das TPACK-Modell (Mishra & Koehler 2006) ist sowohl ein Seminarinhalt, der gemeinsam mit den Studierenden und im Hinblick auf die Planung eigener Unterrichtseinheiten behandelt wird, als auch eine theoretische Grundlage und Orientierungshilfe für die Konzeptionierung und Planung der einzelnen Sitzungen. Um die Verwendung des Modells bei der Planung des Seminars soll es im folgenden Teil gehen. Das Modell zeigt, welche Wissensbereiche Lehrer:innen verknüpfen müssen, wenn digitale Technologien im Schulunterricht zum Thema gemacht werden. Um effektiv mit digitalen Technologien unterrichten zu können, so die Grundidee, benötigen Lehrer:innen eine Kombination von fachdidaktischen, pädagogischen und technologischen Wissensbeständen. Eine isolierte Technikbetrachtung ist nach dem TPACK-Modell deshalb nicht länger zielführend (Schmid, Krannich & Petko 2020). Das TPACK-Modell stellt eine Erweiterung des Shulman’schen Wissensmodells (Shulman 1987) dar und umfasst sieben Wissensbereiche (s. Abb. 2), von denen vier technologische Komponenten aufweisen. Die technikbezogenen Wissensbereiche stellen bei dem Transfer digitaler Verfahren der Textanalyse in den schulischen Bereich eine große Rolle und werden deshalb im folgenden Teil näher beschrieben. Dabei soll deutlich werden, welche Seminarinhalte welche Wissensbereiche aktivieren. Der Fokus liegt dabei auf Korpusanalyse.
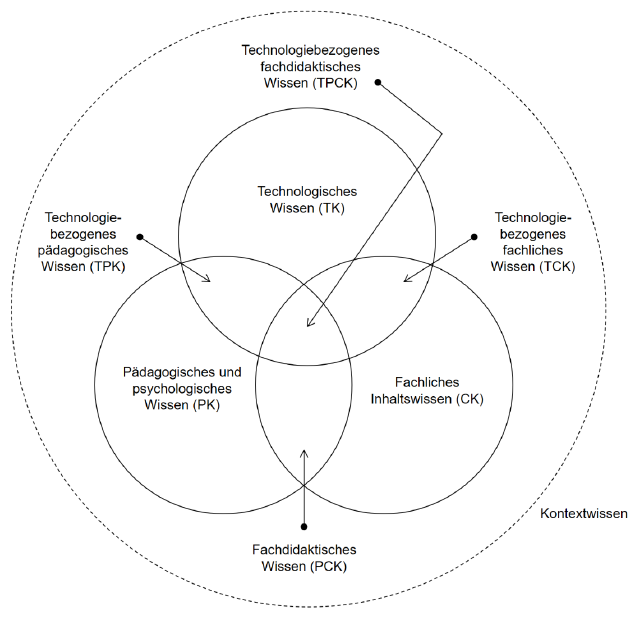
Abbildung 2. TPACK-Modell nach Mishra und Koehler (2006)
Technologisches Wissen (Technological Knowledge, TK): Technologiebezogenes Wissen umfasst Anwendungswissen und konzeptionelles Wissen über aktuelle und relevante Medien und Technologien. Das Anwendungswissen für Notebooks umfasst bspw. Kenntnisse über deren Bedienung, die Installation von Programmen, zur Nutzung oder Erstellung von Inhalten oder über das Beheben von Problemen. Konzeptionelles Wissen umfasst grundlegendes Wissen zur Funktionsweise digitaler Technologien (Schmid, Krannich & Petko 2020, 118). Der im Seminar entscheidende Medientyp sind sicherlich Digitalmedien, die für die computergestützten Literaturanalysen in besonderer Weise verwendet werden. Die Vermittlung der Methodenkompetenz, also die praktische Anwendung der Tools, folgt einem Bring-your-own-device-Ansatz.6 Die Arbeit am eigenen Gerät zielt darauf ab, technologiebezogenes Anwendungswissen direkt am Beispiel der Geräte zu vermitteln, die die Studierenden auch außerhalb des Seminars verwenden. Die Arbeit am eigenen Notebook und der Verzicht auf externe Hardware erhöhen außerdem die Einsteiger:innenfreundlichkeit, da die Studierenden mit einigen Grundfunktionen der Geräte bereits vertraut sind. Die gemeinsame Einarbeitung am eigenen Gerät in Präsenz ist wichtig, um im Zuge einer kleinschrittig erfolgenden Annäherung an die neuen Methoden eventuelle Berührungsängste mit digitalen technischen Verfahren abzubauen. Darüber hinaus ist der Blick über die Schulter auf den Bildschirm der Studierenden gerade bei der Installation und Anwendung der Tools wichtig, um eventuelle Fehler frühzeitig zu erkennen und gemeinsam beheben zu können. Das sog. Trouble Shooting, also die Behebung von Fehlermeldungen, die bereits bei der Installation oder später bei der Anwendung der meisten CLS-Methoden auftreten, wird zum Seminargegenstand und zur Herausforderung, die gemeinschaftlich gemeistert wird. Im Hinblick auf diverse Betriebssysteme und Kenntnisstände über Funktionsweisen und Ordnungsstrukturen der Computer sowie unterschiedliche Nutzungsroutinen der Studierenden erweist sich die Vermittlung von technologiebezogenem Wissen als besonders elementar. Um bspw. mit eigenen Trainingsdaten ein Modelltraining durchzuführen und ein Textkorpus automatisch annotieren zu lassen, muss die Ordnerstruktur des Computers bekannt sein. Das mag trivial klingen, weicht in vielen Fällen aber von den alltäglichen Gebrauchsszenarien der Studierenden ab und sollte deshalb als Seminarinhalt berücksichtigt werden. Dabei gilt es – so meine Perspektive – transparent zu machen, dass Trouble Shooting ein mehr oder weniger präsenter Bestandteil der CLS ist und vermeintlich triviale Angelegenheiten – wie ein fehlendes Leerzeichen im Eingabefeld – über das Gelingen oder Misslingen einer Korpusanalyse entscheiden kann.
Technologiebezogenes fachliches Wissen (Technological Content Knowledge, TCK): „Damit ist Wissen gemeint, das technologisches und schulfachbezogenes Wissen verbindet. Fast jedes Fachgebiet erlebt aktuell Veränderungen im Zusammenhang mit neuen Technologien. [...] Lehrpersonen müssen deshalb wissen, wie Technologien in den Hintergrunddisziplinen ihrer Schulfächer zur Wissensgenerierung, Wissensrepräsentation, Wissensnutzung und Wissenskommunikation eingesetzt werden.“ (Schmid, Krannich & Petko 2020, 119) So auch der Deutschunterricht, als dessen ‘Hintergrunddisziplin’ ich hier die Computational Literary Studies stark machen möchte. Die TCK-Komponente soll das Seminar besonders in der ersten Säule aufgreifen, indem ein Grundstock an digitalen Verfahren der Textanalyse und Verfahren des überwachten und unüberwachten Lernens zur Korpusanalyse theoretisch und praktisch unterrichtet werden und zu einem reflektierten Umgang mit digitalen Verfahren der Textanalyse angeleitet wird. Zum technologiebezogenen Wissen für angehende Deutschlehrer:innen zähle ich eine Einführung in die zentralen Begrifflichkeiten der CLS und ein Kennenlernen der DH als Fachdisziplin sowie eine Einführung in die Korpuskonstituierung. Darüber hinaus gehört die digitale manuelle Annotation (mit dem Textanalysetool CATMA, Gies et al. 2024) als digitales Close-Reading-Verfahren zu den Seminarinhalten. Im Themenkomplex Distant Reading werden Topic Modeling (Orange Data Mining), Sentimentanalyse (SentText), gKI (UHHGPT und FelloFish) und überwachtes maschinelles Lernen (StanfordNER-Toolkit; Finkel, Grenager & Manning 2005) vermittelt.
Technologiebezogenes pädagogisches Wissen (Technological Pedagogical Knowledge, TPK): Mit diesem Wissensbereich ist im deutschsprachigen Raum in der Regel das mediendidaktische (Lernen mit Medien), medienerzieherische oder medienbildnerische (Lernen über Medien) Wissen gemeint (Schmid, Krannich & Petko 2020, 119). Diesen Aspekt greift das Seminar vor allem in der zweiten konzeptuellen Säule auf. Zum einen soll eine Grundlage geschaffen werden, die bestehende mediendidaktische Modelle und bildungspolitische Rahmenbedingungen, die die Unterrichtsplanung und den Schulalltag mitbestimmen, beinhaltet. Zum anderen geht es um eine Rückbindung zwischen Tools und Medien, die im Rahmen der CLS verwendet werden, und Medienmodellen und -typologien, die seitens der Mediendidaktik zur Verfügung stehen. Diesem Wissensbereich nähert sich das Seminar durch die Auseinandersetzung mit bildungspolitischen Rahmenbedingungen und Medientypologien, durch die Auswertung von Studien zum Einsatz digitaler Medien in der Schule und durch die Auseinandersetzung mit medienwissenschaftlichen Modellen (TPACK, SAMR-Modell).
Technologiebezogenes fachdidaktisches Wissen (Technological Pedagogical Content Knowledge, TPCK): In diesem Wissensbereich fallen die Wissensbereiche und Schnittbereiche ohne Technologie-Bezug, fachliches Wissen (CK), pädagogisches und psychologisches Wissen (PK), mit dem technologischen Wissen (TK) zusammen. Dieses Wissen „[...] bezieht sich darauf, wie eine bestimmte Technologie in einem bestimmten Fachgebiet didaktisch sinnvoll eingesetzt werden kann. Dieses hochspezifische Wissen bildet den Kern des TPACK-Modells, da erst in der Kombination sinnvolles Planungs- und Handlungswissen entsteht“ (Schmid, Krannich & Petko 2020, 119). Der globale Seminarverlauf ist an den Teilbereichen der Säulen orientiert. In einer Seminarsitzung steht jeweils die Einarbeitung in ein ausgewähltes Verfahren der digitalen Literaturwissenschaft im Vordergrund, in der darauffolgenden Sitzung ein mediendidaktisches oder literaturdidaktisches Konzept. Beide Säulen werden in möglichst jeder Sitzung am ‘Runden Tisch’ zusammengebracht, um eine isolierte Betrachtungsweise und den Aufbau von Inselwissen in einem Teilbereich zu vermeiden und die Aktivierung von TPCK zu begünstigen. Bei methodisch-praktischen Sitzungen werden Gelingensbedingungen und didaktische Grundlagen für einen Transfer in den schulischen Bereich reflektiert. Bei Sitzungen zu mediendidaktischen Modellen wird überprüft, zu welchen bereits behandelten DH-Methoden dieses Modell passen könnte.
Die übrigen nicht-technologiebezogenen Komponenten des Wissensmodells tauchen im Seminar stetig auf, aber eher als Querschnittsthema und nicht klar durch die Taktung nach Sitzungen abgegrenzt. Die Bereiche pädagogisches und psychologisches Wissen sowie fachdidaktisches Wissen werden in einzelnen Sitzungen und spätestens bei der Anfertigung der Hausarbeiten aufgegriffen. Hier gilt es, vertiefend darzustellen und auszuarbeiten, welche literaturdidaktischen Ansätze auf die CLS-Analyse übertragbar sind, und eigene Ideen für den Unterricht zu entwickeln. Fachliches Inhaltswissen wird durch die Bearbeitung möglichst konkreter Forschungsfragen, die mittels digitaler Verfahren der Textanalyse bearbeitet werden, in jeder Sitzung mit CLS-Schwerpunkt mitbehandelt. Um zu zeigen, mit welchen Methoden welche Fragestellungen beantwortet werden können, eignet sich der Einbezug (im Impulsvortrag oder als vorbereitend zu lesende Seminarlektüre) von Fallstudien und / oder Konferenzabstracts, in denen Analysen in der Regel besonders kurz und bündig vorgestellt werden. Im Sinne der interdisziplinären Brückenbildung erweist es sich außerdem als wichtig, die literaturwissenschaftliche Traditionslinie der digitalen Verfahren sichtbar zu machen (die die Studierenden in vielen Fällen in entsprechenden literaturwissenschaftlichen Fachseminaren bereits kennengelernt haben). Sowohl die manuelle Annotation von Textphänomenen als auch die Analyse epochentypischer Themen und emotionstragender Textstrukturen oder die Frage nach Autor:innenschaft und Schreibstilen gehören zum ‘traditionellen’ literaturwissenschaftlichen Forschungsdiskurs. Der digitale Zugriff auf Einzeltexte oder Textkorpora bietet eine andere Perspektive auf ‘klassische’ literaturwissenschaftliche Forschungsfragen. Er kann neue Erkenntnisse hervorbringen, alte Erkenntnisse in Frage stellen oder diese bestätigen. Dabei bleibt der Rückbezug auf bestehende Forschungsdiskurse und -ergebnisse bei der Auswertung und Interpretation der Ergebnisse digitaler Textanalysen ein genauso elementarer Bestandteil des wissenschaftlichen Arbeitens wie in literaturwissenschaftlichen Analysen, die ohne digitale Komponente auskommen. Dennoch unterscheiden sich Forschungsarbeiten der digitalen Literaturwissenschaft nicht nur inhaltlich, sondern auch formal und im Aufbau, bspw. durch ihr experimentelles Studiendesign, die Zitierweise für digitale Texte und Tools, den Einbezug von Visualisierungen und Datensätzen, von Forschungsbeiträgen aus der nicht-digitalen Literaturwissenschaft. Auch im Hinblick auf die Wissenschaftssprache für Korpusanalysen erweist sich der Einbezug von Fallstudien als Orientierungshilfe. Darüber hinaus können auf das Seminarthema abgestimmte Templates und Leitfäden eine hilfreiche Unterstützung für das Verfassen von Hausarbeiten sein.
4.1 Digitale Textkorpora und Korpusanalysen im Seminar „Digitale Literaturwissenschaft und pädagogische Praxis“
Computerlesbare Textkorpora bilden die Grundlage digitaler Textanalysen und sind ein Querschnittsthema der CLS. Dabei heben Herrmann und Lauer (2018) hervor, dass es trotz möglicher Rückbezüge auf die literaturwissenschaftliche Fachtradition und analog zum sprachwissenschaftlichen Teilbereich der Korpuslinguistik, die Teildisziplin der Korpusliteraturwissenschaft noch nicht gibt (Herrmann & Lauer 2018, 129). Das sei unter anderem darauf zurückzuführen, dass die Literaturwissenschaft und literaturwissenschaftliche Editionen stark am Kanon besonderer Werke ausgerichtet seien (Hermann & Lauer 2018, 127). Im Fokus vieler literaturwissenschaftlicher Arbeiten stehe also eher das Besondere und nicht das Typische: „Besondere Texte werden hier vor allem als exemplarische Belege eingeschaltet oder auch in genaueren Einzelanalysen untersucht, nicht aber in größerem Umfang und zur Beschreibung genereller Trends oder allgemeiner Phänomene kompiliert.“ (Herrmann & Lauer 2018, 127) Nun schafft die Digitalisierung großer Bestände die Grundlage für eine Korpusliteraturwissenschaft, die abseits ausgewählter Einzeltexte oder Werkausgaben kanonisierter Autor:innen arbeitet (Hermann & Lauer 2018, 129) und den als the great unread bezeichneten nicht kanonisierten, zahlenmäßig aber weit überlegeneren Bestandteil der Literaturproduktion, in den Blick zu nehmen (Moretti 2000).7 Das wohl bekannteste und umfangreichste Digitalisierungsprojekt ist sicherlich Google Books mit über 40 Millionen Büchern. Darüber hinaus gibt es historische und gattungsspezifische digitale Sammlungen, bspw. das gattungsübergreifend aufgebaute Deutsche Textarchiv (DTA) mit über 4000 deutschsprachigen Druckwerken aus der Zeit 1600 bis 1900 (Geyken et al. 2018), das Textgrid Repository mit über 600 deutschsprachigen literarischen Texten aus dem 15. bis 20. Jahrhundert (Wegstein, Rapp & Jannidis 2015) oder die Dramensammlung DraCor mit über 700 deutschsprachigen Dramen aus der Zeit zwischen 1510 bis 1947 und weiteren Dramenbeständen aus dem französischen, russischen, spanischen, englischen, niederländischen, italienischen, ungarischen, schwedischen, polnischen, ukrainischen, griechischen oder amerikanischen Sprachraum (Fischer et al. 2019). Unter einer Textsammlung oder einem Textkorpus ist in diesem Beitrag also eine bestehende größere Sammlung von kanonisierten und nicht-kanonisierten Texten gemeint, die meistens nach Epoche, Sprache, Textsorte oder Autor:in zusammengestellt sind. Im Hinblick auf konkrete Untersuchungsfragen, die die Studierenden bspw. in Hausarbeiten ausformulieren, wird aus der Textsammlung in der Regel eine Stichprobe (auch als Teilkorpus bezeichnet) zusammengestellt, anhand dessen der Untersuchungsfrage nachgegangen wird.8
Im Seminarkontext spielen Textsammlungen außerdem eine gleichbleibend große Rolle, wird doch für jedes Verfahren und jede Beispielanalyse ein Textkorpus benötigt, mit dem geübt und gearbeitet werden kann.
In einer einführenden Sitzung zum Thema Korpuskonstituierung werden zunächst etablierte, wissenschaftlich valide Datenquellen vorgestellt und unter quellenkritischer sowie didaktischer Perspektive diskutiert. Für diese Sitzung lesen die Studierenden vorbereitend einen Fachtext, der wissenschaftlich fundiert und niedrigschwellig in die literaturwissenschaftliche Korpusbildung einführt und via forTEXT – einer digitalen Plattform mit einsteiger:innenfreundlich aufbereiteten Einführungstexten zu Methoden der digitalen Textanalyse – zur Verfügung gestellt wird (Bläß 2024 [2020]). Im Seminar selbst folgt auf eine kurze Diskussion des Fachtextes eine theoretische Einführung in die Korpuskonstituierung mitsamt Kriterien zum Aufbau von Datensammlungen (nach Schöch 2017). Anschließend arbeiten die Studierenden in Kleingruppen mit unterschiedlichen digitalen Textsammlungen aus dem Bereich der digitalen Literaturwissenschaft. Dabei halten sie fest, welcher Sammelschwerpunkt dem Repositorium zugrunde liegt, in welchen Formaten die Texte angeboten werden und welche Filterfunktionen, implementierten Analysetools und Kriterien zur Qualitätskontrolle vorliegen. Darüber hinaus skizziert jede Kleingruppe ein Unterrichtsszenario, das sich mit dem von ihnen geprüften digitalen Repositorium verbinden ließe. Im Rahmen der Unterrichtsplanung üben sie außerdem den Download und das strukturierte Anlegen größerer thematisch kuratierter Textkorpora. Das mag trivial klingen, ist für viele Studierende aber absolutes Neuland. Die Beschäftigung mit Korpusbildung und der Umgang mit digitalen Quellen sind in der Literaturwissenschaft relativ neue Gegenstandsbereiche, sodass fundiertes Vorwissen nicht vorausgesetzt werden kann. Im Plenum werden die unterschiedlichen digitalen Sammlungen kurz vorgestellt und die Unterrichtsideen diskutiert. Die Sitzung zu digitalen Repositorien zielt vor allem darauf ab, digitale Textkorpora vorzustellen, mit denen die Studierenden im weiteren Seminarverlauf immer wieder arbeiten werden und auf die sie auch im Rahmen ihrer Arbeit an Schulen zurückgreifen können. Die Arbeit mit Textkorpora spielt im weiteren Seminarverlauf bei der Auseinandersetzung mit ganz unterschiedlichen Seminarinhalten eine wiederkehrende Rolle (s. Tabelle 1).
|
Textkorpus |
Seminarinhalt |
|
|
1 |
‘Korpus bildungspolitische Schlüsseltexte’: KMK-Strategie „Bildung in der digitalen Welt“, Erweiterung der KMK-Strategie, Dagstuhl Erklärung, Erweiterung der Dagstuhl-Erklärung, Strategiepapier der Gesellschaft für Fachdidaktik (GFD) „Fachliche Bildung in der digitalen Welt“, DigitalPakt Schule |
bildungspolitische Rahmenbedingungen |
|
2 |
d-Prose 1870–1920 (2511 literarische Prosatexte) |
Distant Reading mit Voyant |
|
3 |
d-RoRo (115 Romane aus der Romantik) |
Stilometrische Analyse mit Stylo |
|
4 |
TextGrid Repository, Fantasykorpus |
Sentimentanalysis mit SentText |
|
5 |
Deutsches Textarchiv und / oder Andersen-Korpus |
Topic Modeling |
|
6 |
Prompt-a-thon mit UHHGPT9 und FelloFish |
Tabelle 1. Textkorpora und ausgewählte Sitzungsinhalte im Überblick
Nachdem im vorangegangenen Teil die Sitzungsinhalte vorgestellt wurden, in denen Textkorpora eine besonders wichtige Rolle spielen, soll im folgenden Teil unter Einbezug des TPACK-Modells erläutert werden, welche Wissensbereiche bei der Verbindung von Korpusliteraturwissenschaft und Schule aktiviert werden.
Technologiebezogenes Wissen umfasst nicht nur das Wissen über die Anwendung digitaler Verfahren der Textanalyse, die für Korpusanalysen eingesetzt werden können. Neben einem Überblick über bestehende Korpora, die nachgenutzt werden können, gehören auch Kenntnisse über den Download digitaler Textsammlungen, grundlegende Formatierungsarbeiten sowie Schritte des Preprocessing zum technologiebezogenen Wissen für Korpusanalysen. Konzeptionelles Wissen beinhaltet grundlegendes Wissen über Fachbegriffe aus dem Bereich der Korpuskonstituierung und Korpusanalyse, Strategien zum Aufbau von Datensammlungen und eine Auseinandersetzung mit Bias-Problematiken, die mit dem Aufbau von Datensammlung und deren Analyse einhergehen.
Im Bereich des technologiebezogenen fachlichen Wissens steht der Transfer digitaler Verfahren in den Literaturunterricht im Vordergrund. Ein Einbezug des „schulfachbezogenen Wissens“ bedeutet im Falle einer Korpusanalyse ein Abgleichen mit und Andocken an fachliche und jahrgangsspezifische Anforderungen (Lehrpläne für das Unterrichtsfach Deutsch, Bildungsstandards und KMK-Kompetenzen). Dabei geben die fachlichen Anforderungen einen Rahmen für die Korpuskonstituierung, indem sie bspw. die Auseinandersetzung mit ausgewählten Epochen und Gattungen vorschreiben und dadurch eine entsprechende Korpuskonstituierung nahelegen. Wenn bspw. im Textgrid-Repository eine Sammlung mit allen Märchen von Hans Christian Andersen im TXT-Format heruntergeladen wurde, müsste die geplante digitale Märchenanalyse im Lehrplan verortet werden und – je nach Methode der Korpusanalyse – eine KMK-Kompetenz herausgestellt werden, die im Rahmen der Unterrichtsstunde oder -einheit geschärft werden soll. Soll die Funktionsweise von Algorithmen diskutiert werden, bietet sich als Methode zur Analyse des Märchenkorpus ein Distant-Reading-Verfahren an. Im Hinblick auf eine fiktive Lerngruppe gilt es dann, einen passenden Unterrichtsentwurf zu entwickeln, der konkrete Lernziele und Unterrichtsmaterialien (Arbeitsblätter, Anleitung durch die Lehrkraft etc.) beinhaltet. Dazu muss die Analyse zunächst einmal selbst durchgeführt werden und dann für den Schulunterricht quasi in Einzelteile zerlegt werden, die für Schüler:innen umsetzbar sind. Die Verortung von Korpusanalysen im TPACK-Modell offenbart die unterschiedlichen Wissensbereiche, die im Hinblick auf Korpusanalysen für angehende Lehrkräfte von Bedeutung sind. Technologiebezogenes fachdidaktisches Wissen bedeutet im Hinblick auf Korpusanalysen in den meisten Fällen eine Reduktion der Komplexität. Nachdem die Studierenden Funktionsweise und Einsatz digitaler Verfahren der Korpusanalyse erlernt haben, müssen sie identifizieren, welche Komponenten unmodifiziert in den Schulunterricht übertragen werden können und welche Komponenten im Hinblick auf die (fiktive) Lerngruppe und das schulfachbezogene Wissen modifiziert werden sollten. In dieser Transferleistung liegt eine große Herausforderung. Sie kann im Seminar durch Diskussionen von Unterrichtskonzepten angebahnt werden und im Rahmen von Hausarbeiten weiter ausgearbeitet werden.
5 CLS-Korpusmethodik in der Lehre: Seminarresultate und abschließende Überlegungen
Wie die Verortung der am Brückenschlag zwischen CLS und Didaktik beteiligten Wissensbereiche gezeigt hat, erfordert das Seminar vor allem Transferleistungen. Die Verfahren der CLS stehen zwar in einer langen literaturwissenschaftlichen Traditionslinie und dürften in Grundzügen bekannt sein, sie erfordern neben der reinen Anwendungskompetenz aber auch einen neuen Blick auf die Analyse literarischer Texte. Von der Auswahl der Texte über die Definition des Phänomens bis zur Durchführung der Analyse und der Auswertung der Ergebnisse sind alle Arbeitsschritte an den Prämissen quantitativer Analysen ausgerichtet. Ein quantitativer Zugriff auf literarische Texte ist für die Studierenden in der Regel absolutes Neuland. Darüber hinaus ist auch die Übertragung in den schulischen Bereich herausfordernd, da die ‘frisch’ erlernten CLS-Verfahren mit den Anforderungen einer fiktiven Lerngruppe abgeglichen und an die Kompetenzbereiche und Bildungsstandards angedockt werden müssen. Damit diese Transferleistungen gelingen, braucht es – neben der reinen Vermittlung von Fachwissen aus dem Bereich CLS und Didaktik – vor allem praktische Übung, Zeit und intensiven diskursiven Austausch. In einer zweiten Durchführung des Seminars im Wintersemester 2024/25 wurde ein Teil des Seminars im Block durchgeführt. Gerade im Hinblick auf komplexere Verfahren, in diesem Fall das Machine-Learning-Training eines Classifiers zur automatischen Annotation und eine damit vorgesehene Korpusanalyse, erweist sich das Blockseminar als Format der Wahl. Für das Modelltraining, die Anwendung des Classifiers, die Analyse und deren Auswertung braucht es – noch dringender als bei den übrigen Verfahren – Zeit am Stück für die technische Einarbeitung.
Im gesamten Seminar erweisen sich digitale Repositorien als wichtige Grundlage. Korpusanalysen stellen ein Querschnittsthema dar, wobei unterschiedliche Textkorpora jeweils im Rahmen von unterschiedlichen Analyseverfahren wie Stilometrie, Topic Modeling, Sentimentanalyse oder mithilfe automatischer Annotation untersucht werden.
Angesichts der vorgesehenen Kompetenzorientierung äußern sich die Studierenden oft kritisch bis ratlos. Im Gespräch wird immer wieder der Wunsch nach praktischen Anwendungsszenarien und konkreten Beispielen artikuliert, die zeigen, wie genau Literaturunterricht mit digitaler Komponente aussehen kann. Dass in Form der CLS eine Verbindung zwischen Algorithmen und Literatur besteht, wird in der Regel beinahe erleichtert, neugierig und gleichzeitig kritisch-abwartend wahrgenommen. Kann Literatur wirklich digital erforscht werden? Werden digitale Verfahren der Spezifik literarischer Texte gerecht? Welche Fachinhalte des Literaturunterrichts passen zu welcher CLS-Methode? Welche Phänomene erfasst der Computer anders als der Mensch und: Geht eine digitale Korpusanalyse wirklich immer schneller? Diese und viele weitere Fragen sind wiederkehrende Diskussionsinhalte des Seminars.
Der Blick auf die bereits eingegangenen Abschlussarbeiten zeigt, dass die Studierenden kreative und kluge Ideen für den Literaturunterricht mit digitaler Komponente entwickeln. So wurden bspw. Unterrichtsentwürfe zum Thema digitale Annotation mit dem Textanalysetool CATMA am Beispiel des Romans Ellbogen von Fatma Aydemir oder „Eine didaktische Annäherung am Beispiel von Wolfgang Borcherts Kurzgeschichte Das Brot“ ausgearbeitet. Weitere Hausarbeiten befassen sich mit der Anwendung von Sentimentanalyse oder dem Distant-Reading-Tool Voyant im Literaturunterricht – und sogar eine Bachelorarbeit zum Thema „Digital Humanities im Deutschunterricht – Voraussetzungen und Strategien für den Transfer in den schulischen Bereich“ ist aus dem Seminar hervorgegangen. Im Hinblick auf die Hausarbeiten fällt auf, dass die meisten Studierenden Thema und Untersuchungsfrage so wählen, dass eine digitale Analyse eines Einzeltextes durchgeführt werden kann. Unter methodischer Perspektive war die digitale manuelle Annotation mit dem Textanalysetool CATMA eindeutig am beliebtesten, wobei das Tool zur Analyse unterschiedlicher Phänomene und Texte herangezogen wurde und unterschiedliche Szenarien für den Schulunterricht entwickelt wurden.
Abschließend möchte ich noch einmal auf die im ersten Teil skizzierte und aktuell sehr lebendige Debatte über gKI in der Lehre zurückkommen. Die Auseinandersetzung mit gängigen Verfahren der digitalen Literaturwissenschaft, wie manuelle Annotation und Machine-Learning-Verfahren, bilden eine Brücke hin zum Verständnis von komplexeren Verfahren und Zusammenhängen, wie der Funktionsweise von LLMs. Die Seminarinhalte sind also bewusst so angeordnet, dass sie markante Entwicklungsstufen der CLS wiedergeben und der Komplexitätsgrad langsam steigt. Nun legt die aktuelle bildungspolitische Debatte einen Fokus auf die Auseinandersetzung mit LLMs nahe. Die Auseinandersetzung mit Sprachmodellen zu priorisieren und isoliert von den Grundlagen der CLS zu betrachten, hieße in gewisser Weise, das Pferd von hinten aufzäumen. CLS-Grundlagenwissen bildet den Ausgangspunkt für ein tiefergehendes und kritisch-reflektiertes Verständnis von Tools und Verfahren, die mit gKI arbeiten. Die Auseinandersetzung mit gKI und deren Funktionsweisen baut auf Grundlagenwissen der CLS auf. Um die Empfehlungen der Ständigen Wissenschaftlichen Kommission nachkommen zu können und einen hinreichenden Wissensaufbau zu ermöglichen, bedarf es aus meiner Perspektive eines sukzessiven Wissensaufbaus (ausgehend von den CLS-Grundlagen) und keines Ad-hoc-Einstiegs beim komplexesten Lerninhalt (Funktionsweise und Anwendung generativer KI).
In einer der wenigen deutschsprachigen Einführungen in die Digital Humanities werden vier Bereiche benannt, die in der Literaturwissenschaft im Kontext der Digitalisierung und Vernetzung Veränderungen erfahren haben. Beides, sowohl die Digitalisierung als auch eine dadurch erhöhte Vernetzung mit anderen Fachbereichen, betreffen den Gegenstandsbereich der Literaturwissenschaft, wozu hier vor allem Texte gezählt werden (1). Eine Veränderung erfahren außerdem die Kommunikation über Texte (2), die Methoden zu deren Aufbereitung und die Analyseverfahren (3) und die Zusammenarbeit mit Archiven und Bibliotheken (4) (Jannidis 2022, 1 f.). Abschließend möchte ich die Lehre, also die Vermittlung von literaturwissenschaftlichem Wissen und literaturwissenschaftlichen Fertigkeiten, als fünften und weiteren Teilbereich der Literaturwissenschaft stark machen. Verändern sich die Fachinhalte, so verändern sich auch die Lehrinhalte und die Art und Weise, sie zu vermitteln. Einem Verständnis wissenschaftlicher Verwandtschaftsverhältnisse folgend, das Deutschdidaktik und nicht-digitale Literaturwissenschaft als (dialogbedürftige) Bezugswissenschaften betrachtet (Boyken 2016, 34), begreife ich die digitale Literaturwissenschaft auch als Bezugswissenschaft der Literaturdidaktik. Die zielgruppenorientierte Vermittlung einer literaturwissenschaftlichen Grundausbildung oder Basiskompetenz fasse ich als weiteren Teilbereich auf, der durch die Digitalisierung und Vernetzung eine Veränderung erfährt. Zielgruppenorientierung bedeutet in diesem Fall, dass angehende Lehrkräfte einen Grundstock an Verfahren der literaturwissenschaftlichen Korpusanalyse kennenlernen und dazu angeregt werden, den Transfer in den Schulunterricht bereits in der ersten Ausbildungsphase mitzudenken. Da Technologien schnelllebig sind, ist es außerdem wichtig, Studierende über den universitären Kontext hinaus dazu zu befähigen, aus dem breiten Spektrum eigenständig eine fundierte und lerngruppenorientierte Auswahl treffen zu können. Neben der Einarbeitung in die Methoden wird insbesondere die Frage der Komplexitätsreduktion und des schulischen Anwendungsbezuges immer wieder durchdacht und neu verhandelt werden müssen. Um begründet beurteilen zu können, welche Analyseverfahren und Tools sich für den Einsatz im Schulunterricht eignen und welche nicht, müssen die unterschiedlichen Wissensbereiche ‘angezapft’ und miteinander in Verbindung gesetzt werden. Auf diese Transferleistung möchte der vorliegende Beitrag aufmerksam machen und in Form des oben skizzierten Seminarkonzepts einen Vorschlag zur Diskussion stellen, der die Vermittlung und Vernetzung von Fachwissen aus unterschiedlichen Bereichen vorsieht.
References
Albrecht, Christian. 2014. A6 Fachspezifische mediendidaktische Konzeptionen. Digitale Medien im Deutschunterricht. Deutschunterricht in Theorie und Praxis. Handbuch zur Didaktik der deutschen Sprache und Literatur in elf Bänden. Band 8. Volker Frederking, Axel Krommer & Thomas Möbius, Hg. Baltmannsweiler: Schneider Verlag Hohengehren. 134–149.
Andresen, Melanie. 2024. Computerlinguistische Methoden für die Digital Humanities. Eine Einführung für Geisteswissenschaftler:innen. Tübingen: Narr Francke.
Archer, Jodie & Matthew L. Jockers. 2017. Der Bestseller Code. Was uns ein bahnbrechender Algorithmus über Bücher, Storys und das Lesen verrät. New York: St. Martin’s Press.
Aßmann, Sandra. 2017. Medienpolitische Positionen, Forderungen und Strategien. Medienkompetenz. Herausforderung für Politik, politische Bildung und Medienbildung. Harald Gapski, Monika Oberle & Walter Staufer, Hg. Bonn: Bundeszentrale für politische Bildung. 136–145.
Battershill, Claire & Shawna Ross. 2022. Using Digital Humanities in the Classroom: A practical introduction for teachers, lecturers, and students. London: Bloomsbury Academic.
Bläß, Sandra. 2024 [2020]. Methodenbeitrag: Korpusbildung. forTEXT 1 (2). https://doi.org/10.48694/fortext.3808
Bläß, Sandra, Marie Flüh, Dominik Gerstorfer, Evelyn Gius, Malter Meister, Julia Nantke & Mareike Schumacher. 2022. Forschendes Lernen digital. DHd 2022 Kulturen des digitalen Gedächtnisses. 8. Tagung des Verbands Digital Humanities im deutschsprachigen Raum (DHd 2022), Potsdam. https://doi.org/10.5281/ZENODO.6327933
Boyken, Thomas. 2016. Über wissenschaftliche Verwandtschaftsverhältnisse. Versuch einer Einordnung der aktuellen Entwicklungen innerhalb der Deutschdidaktik aus literaturwissenschaftlicher Sicht. Interdisziplinäre Forschung in der Deutschdidaktik. „Fremde Schwestern“ im Dialog. Positionen der Deutschdidaktik. Theorie und Empirie. Band 2. Iris Winkler & Frederike Schmidt, Hg. Frankfurt am Main: Peter Lang. 23–41.
Brand, Tilman von. 2015. Umgang mit Medien. Methoden im Deutschunterricht. Exemplarische Lernwege für die Sekundarstufe I und II. Tilman von Brand, Jürgen Baurmann, Wolfgang Menzel & Kaspar H. Spinner, Hg. Seelze: Kallmeyer Klett. 107–136.
Cardoso, Amílcar, Tony Veale & Geraint Anthony Wiggins. 2009. Converging on the divergent: The history (and future) of the international joint workshops in computational creativity. AI magazine 30 (3), 15–22. https://doi.org/10.1609/aimag.v30i3.2252
Cohen, Margaret. 1999. The Sentimental Education of the Novel. Princeton (NJ): Princeton University Press.
digital.learning.lab. https://digitallearninglab.de/. Zugriff: 7. Februar 2025.
FelloFish – Feedack für alle. https://www.fellofish.com/. Zugriff: 24. April 2025.
Finkel, Jenny Rose, Trond Grenager & Christopher Manning. 2005. Incorporating Non-local Information into Information Extraction Systems by Gibbs Sampling. Proceedings of the 43nd Annual Meeting of the Association for Computational Linguistics (ACL 2005), 363–370. Available at: http://nlp.stanford.edu/~manning/papers/gibbscrf3.pdf. Zugriff: 24. April 2025.
Fischer, Frank, Ingo Börner, Mathias Göbel, Angelika Hechtl, Christopher Kittel, Carsten Milling & Peer Trilcke. 2019. Programmable Corpora: Introducing DraCor, an Infrastructure for the Research on European Drama. Proceedings of DH2019: „Complexities“. Utrecht University. https://doi.org/10.5281/zenodo.4284002
Flüh, Marie. 2024 [2020]. Schulunterricht: Textanalyse mit CATMA unterrichten. forTEXT 1 (4). https://doi.org/10.48694/fortext.3755
Flüh, Marie 2024a [2019]. Schulunterricht: Textvisualisierung mit Voyant unterrichten. forTEXT 1 (5). https://doi.org/10.48694/fortext.3774
Flüh, Marie 2024b [2019]. Lehrmodul: Netzwerkanalyse mit Ezlinavis unterrichten. forTEXT 1 (6). https://doi.org/10.48694/fortext.3781
Frederking, Volker & Axel Krommer. 2014. A7 Deutschunterricht und mediale Bildung im Zeichen der Digitalisierung. Digitale Medien im Deutschunterricht. Deutschunterricht in Theorie und Praxis. Handbuch zur Didaktik der deutschen Sprache und Literatur in elf Bänden. Band 8. Volker Frederking, Axel Krommer & Thomas Möbius, Hg. Baltmannsweiler: Schneider Verlag Hohengehren. 150–182.
Geyken, Alexander, Matthias Boenig, Susanne Haaf, Bryan Jurish, Christian Thomas & Frank Wiegand. 2018. Das Deutsche Textarchiv als Forschungsplattform für historische Daten in CLARIN. Digitale Infrastrukturen für die germanistische Forschung. Henning Lobin, Roman Schneider & Andreas Witt, Hg. Berlin, Boston: de Gruyter. 219–248.
Gius, Evelyn, Jan Christoph Meister, Malte Meister, Marco Petris, Dominik Gerstorfer & Mari Akazawa. 2024. CATMA 7 (Version 7.1). Zenodo. https://doi.org/10.5281/zenodo.1470118
Herrmann, Berenike & Gerhard Lauer. 2018. Korpusliteraturwissenschaft. Zur Konzeption und Praxis am Beispiel eines Korpus zur literarischen Moderne. Korpuslinguistik. Joachim Gessinger, Angelika Redder & Ulrich Schmitz, Hg. Bielefeld: Account. 127–155.
Hirsch, Brett D. 2015. Digital humanities pedagogy: practices, principles and politics. Cambridge: OpenBook Publishers.
Jackaki, Diane & Katherine Faull. 2016. Doing DH in the classroom: transforming the humanities curriculum through digital engagement. Doing Digital Humanities. Practice, Training, Research. Constance Crompton, Richard Lane & Ray Siemens, eds. New York: Routledge. 385–373.
Jannidis, Fotis. 2010. Methoden der computergestützten Textanalyse. Methoden der literatur- und kulturwissenschaftlichen Textanalyse. Ansätze – Grundlagen – Modellanalyse. Vera Nünning & Ansgar Nünnung, Hg. Stuttgart, Weimar: Metzler. 109–132.
Jannidis, Fotis. 2022. Digitale Literaturwissenschaft. Zur Einführung. Digitale Literaturwissenschaft. Germanistische Symposien. Fotis Jannidis, Hg. Stuttgart: Metzler. 1–19. https://doi.org/10.1007/978-3-476-05886-7_1
Kröncke, Merten, Leonard Konle, Simone Winko, Simone & Fotis Jannidis. 2023. Gattungen und Emotionen in der Lyrik des Realismus und der frühen Moderne. Book of Abstracts DHd 2023 Open Humanities Open Culture. 9. Tagung des Verbands „Digital Humanities im deutschsprachigen Raum“ (DHd 2023). Trier, Luxemburg. https://doi.org/10.5281/zenodo.7715402
KMK 2016 = Konferenz der Kultusminister der Länder in der Bundesrepublik Deutschland (KMK). 2016. Strategie „Bildung in der digitalen Welt“. Berlin 2016. Available at: https://www.kmk.org/aktuelles/artikelansicht/strategie-bildung-in-der-digitalen-welt.html.
Kühnert, Janina. 2017. Fachdidaktisches Essay: Beispielhafte Konzeption einer Literaturunterrichtseinheit mit Voyant. Skriptorium 6 (2017), 41–59.
Lauer, Gerhard. 2013. Die Vermessung der Kultur. Geisteswissenschaften als Digital Humanities. Big Data. Das neue Versprechen der Allwissenheit. Heinrich Geiselberger & Tobias Moorstedt, Hg. Frankfurt am Main: Suhrkamp. 99–116.
Lecke, Bodo. 2008. Medienpädagogik, Literaturdidaktik und Deutschunterricht. Deutsch-Didaktik. Leitfaden für die Sekundarstufe I und II. Michael Kämpfer-van-den Boogaart, Hg. Berlin. 46–57.
Leubner, Martin. 2014. B1 Digitale literale Medien im Deutschunterricht. Digitale Medien im Deutschunterricht. Deutschunterricht in Theorie und Praxis. Handbuch zur Didaktik der deutschen Sprache und Literatur in elf Bänden. Band 8. Volker Frederking, Axel Krommer & Thomas Möbius, Hg. Baltmannsweiler: Schneider Verlag Hohengehren. 185–212.
Limpinsel, Mirco. 2016. Was bedeutet die Digitalisierung für den Gegenstand der Literaturwissenschaft? Zeitschrift für digitale Geisteswissenschaften 1 (2016). http://dx.doi.org/10.17175/2016_009
Mahony, Simon & Elena Pierazzo. 2015. Teaching Skills or Teaching Methodology? Digital humanities pedagogy: practices, principles and politics. Brett D. Hirsch, ed. Cambridge: OpenBook Publishers. 215–225. Available at: https://books.openedition.org/obp/1639.
Mauro, Aaron. 2016. Digital liberal arts and project-based pedagogies. Doing Digital Humanities. Practice, Training, Research. Constance Crompton, Richard Lane & Ray Siemens, eds. New York: Routledge. 373–384.
Mischke, Dennis, Peer Trilcke & Henny Sluyter-Gäthje. 2022. Hackathons als kollektiv-kreative Bildungsereignisse. Ein Konzept zur Gestaltung offener Lehrveranstaltungen in den Digital Humanities. DHd 2022 Kulturen des digitalen Gedächtnisses. 8. Tagung des Verbands „Digital Humanities im deutschsprachigen Raum“ (DHd 2022), Potsdam. https://doi.org/10.5281/zenodo.6328099
Mishra, Punya & Matthew J. Koehler. 2006. Technological Pedagogical Content Knowledge: A Framework for Teacher Knowledge. Teachers College Record 108 (6), 1017–1054.
Moretti, Franco. 2000. Conjectures on World Literature. New Left Review 1 (2000), 54–68. Available at: https://tinyurl.com/moretti2000conjwl. Zugriff: 24. April 2025.
Moretti, Franco. 2016. Distant Reading. Konstanz: Konstanz University Press.
MUNDO. https://mundo.schule/. Zugriff: 7. Februar 2025.
Organe Data Mining. https://orangedatamining.com/. Zugriff: 7. Februar 2025.
Risam, Roopika. 2019. New digital worlds: postcolonial digital humanities in theory, praxis, and pedagogy. Illinois: Northwestern University Press.
Sahle, Patrick. 2015. Digital Humanities? Gibt’s doch gar nicht! Grenzen und Möglichkeiten der Digital Humanities. Sonderband der Zeitschrift für digitale Geisteswissenschaften. Constanze Baum & Thomas Stäcker, Hg. text/html Format. https://doi.org/10.17175/sb001_004
Schmid, Mirjam, Maike Krannich & Dominik Petko. 2022. Technological Pedagogical Content Knowledge. Entwicklungen und Implikationen. Journal für LehrerInnenbildung 20 (2020) 1, 116–124. https://doi.org/10.35468/jlb-01-2020_10
Schöch, Christof. 2017. Aufbau von Datensammlungen. Digital Humanities: Eine Einführung. Fotis Jannidis, Hubertus Kohle & Malte Rehbein, Hg. Stuttgart: Metzler. 223–232.
Schumacher, Mareike. 2022. Wie ›Der Mann auf dem Hochrad‹ den Protagonisten des ›Schlangenbaums‹ auf Abwege führte. Hypothesengeleitete stilometrische Untersuchung zweier Romane Uwe Timms. Zeitschrift für digitale Geisteswissenschaften. Wolfenbüttel 2022. https://doi.org/10.17175/2022_004
Schumacher, Mareike & Marie Flüh. 2023. Made to Be a Woman: A case study on the categorization of gender using an individuation-based approach in the analysis of literary texts. Digital Humanities Quarterly – Special Issue: Categories in Digital Humanities 17 (3). Dominik Gerstorfer, Evelyn Gius & Janina Jacke, Hg. https://doi.org/10.17175/2022_004
SentText. https://thomasschmidtur.pythonanywhere.com/. Zugriff: 7. Februar 2025.
Shanahan, Murray & Catherine Clarke. 2023. Evaluating large language model creativity from a literary perspective. ArXiv. https://doi.org/10.48550/arXiv.2312.03746
Shulman, Lee. 1987. Knowledge and Teaching: Foundations of the New Reform. Harvard Educational Review (57), 1–22.
Stanford NER-Toolkit. https://nlp.stanford.edu/software/CRF-NER.html. Zugriff: 5. Februar 2025.
Stylo. https://github.com/computationalstylistics/stylo. Zugriff: 24. April 2025.
SWK 2024 = Ständige Wissenschaftliche Kommission (SWK) der KMK. 2024. Large Language Models (LLM) und ihre Potenziale im Bildungssystem. Available at: https://www.kmk.org/fileadmin/Dateien/pdf/KMK/SWK/2024/SWK-2024-Impulspapier_LargeLanguageModels.pdf. Zugriff: 5. Februar 2025.
Tillmann, Angela. 2017. Informationsverhalten von Kindern und Jugendlichen in digital-vernetzten Welten. Medienkompetenz. Herausforderung für Politik, politische Bildung und Medienbildung. Harald Gapski, Monika Oberle & Walter Staufer, Hg. Bonn: Bundeszentrale für politische Bildung. 116–125.
UHHGPT. https://uhhgpt.uni-hamburg.de/login.php. Zugriff: 24. April 2025.
Urs, Henning. 2021. Sentimentanalyse mit SentText. Available at: https://web2-unterricht.ch/digitale-transformation/sentimentanalyse-mit-senttext/. Zugriff: 7. Februar 2025.
Voyant. https://voyant-tools.org. Zugriff: 7. Februar 2025.
Wampfler, Philippe. 2017. Digitaler Deutschunterricht: Neue Medien produktiv einsetzen. Göttingen: Vandenhoeck & Ruprecht.
Wegstein, Werner, Andrea Rapp & Fotis Jannidis. 2015. Textgrid – eine Geschichte. TextGrid: Von der Community – für die Community. Eine Virtuelle Forschungsumgebung für die Geisteswissenschaften. Heike Neuroth, Andrea Rapp & Sibylle Söring, Hg. Glückstadt: Hülsbusch. 23–35.
Weitin, Thomas & Katharina Herget. 2017. Falkentopics: Über einige Probleme beim Topic Modeling literarischer Texte. Zeitschrift für Literaturwissenschaft 47 (1). https://doi.org/10.1007/s41244-017-0049-3
Yang Zhen, Zhengliang Liu, , , , , , , , , , , , , , , , , , , & . 2024. Analyzing Nobel Prize Literature with Large Language Models.
Zierer, Klaus. 2018. Lernen 4.0. Pädagogik vor Technik. Möglichkeiten und Grenzen einer Digitalisierung im Bildungsbereich. Baltmannsweiler: Schneider Verlag Hohengehren.
1 Unter kulturgeschichtlicher Perspektive auf Medientypen und Mediennutzung lassen sich vier Paradigmen unterscheiden, in denen sich unterschiedliche Medientypen als Leitmedien herausgebildet haben. Das orale Paradigma bestimmt die gesprochene Sprache. Die Stimme fungiert als Primärmedium des vorliteralen Stadiums (Frederking, Krommer & Maiwald 2018, 27). Die Erfindung der Schrift führte zum ersten medialen Paradigmenwechsel und zum Beginn des literalen Paradigmas. Leitmedien waren skripturale Medien und typographische Medien, also an verschiedene Trägermedien gebundenen Formen von Schriftlichkeit (Frederking, Krommer & Maiwald 2018, 29). Durch die Erfindung des Buchdrucks im Jahr 1450 gewinnen neben handschriftlichen Erzeugnissen (skripturale Medien) druckmaschinelle Massenfertigungen (typographische Medien) an Bedeutung; das gedruckte Buch wird zum Leitmedium. In der zweiten Hälfte des 19. Jahrhunderts endete mit der industriellen Revolution die Vorherrschaft des literalen Paradigmas. Die medialen Optionen erweitern sich um akustisch-auditive Medien (Grammophon, Telefon, Rundfunk / Radio, Schallplatte, Tonbandvorläufer), optisch-visuelle Medien (Fotografien als optische Speichermedien, Film) und audiovisuelle Medien (Verbindung von Bild und Ton im Tonfilm, Fernsehen) (Frederking, Krommer & Maiwald 2018, 41). Ein vierter Paradigmenwechsel hin zum digital-multimedialen Paradigma ereignet sich in den 1980er Jahren durch die Entwicklung des Digitalmediums. Die Entwicklung des Internets in den 1980er Jahren bildet die Grundlage für weitere Meilensteine des digital-multimedialen Paradigmas, beispielsweise das Aufkommen sozialer Netzwerke und Cloud-Technologien (Frederking, Krommer & Maiwald 2018, 58) sowie die damit einhergehende immens steigende Datenproduktion, die wiederum die Grundlage für große Sprachmodelle und künstliche Intelligenz bildet. Dieses Paradigma zeichnet eine Medienverschmelzung aus. Leitmedien des digital-multimedialen Paradigmas stellen multimediale Integrationsmedien / Digitalmedien dar. Der Computer kann als Trägermedium alle medialen Präsentationsformen bedienen. Er ermöglicht eine Verbindung von schriftsprachlichen Texturen mit piktoralen, auditiven und audiovisuellen Elementen. In diesem Sinne wird er als Symmedium beschrieben (Frederking, Krommer & Maiwald 2018, 53). Die schulische Medienbildung adressiert unterschiedliche Medientypen und Medientechnologien. Heute liegt der Fokus besonders auf der Auseinandersetzung mit Digitalmedien und damit verbundenen Medientechnologien. In diesem Beitrag geht es vorrangig um den Computer (= Trägermedium), der als Forschungsinstrument eingesetzt wird, um literarische Texte zu analysieren.
2 Die im Deutschunterricht vorkommenden digitalen Medien können nach Leubner (2014) unterschieden werden in literale Medien, auditive Medien, audiovisuelle Medien, Schreib-, Präsentations- und Publikationsmedien, Informations- und Kommunikationsmedien und Interaktions- und Handlungsmedien. Für diesen Artikel stellen digitale literale Medien die relevante Bezugsgröße dar. Die anderen Medienformen klammere ich aus. Digitale literale Medien unterscheiden sich von multimedialen digitalen Produktionen und von schriftsprachlichen Produktionen mit digitaler Druckvorlage, die als Druckversion publiziert sind. Digitale literale Medien umfassen sämtliche Medienproduktionen „[...], die auf Schriftsprache beschränkt oder zumindest im Wesentlichen konzentriert sind und in digitaler Form gespeichert bzw. publiziert vorliegen“ (Leubner 2014, 186). Digitale literale Medienproduktionen lassen sich wiederum in die zwei Haupttypen digital publizierter Texte und digitaler Literatur unterscheiden.
3 Der DigitalPakt Schule ist eine durch das Bundesministerium für Bildung und Forschung koordinierte Fördermaßnahme für den Ausbau der technischen Infrastruktur an Schulen in ganz Deutschland.
4 Für eine Definition überwachter und unüberwachter Verfahren des maschinellen Lernens und deren Einsatz in den Geisteswissenschaften vgl. Andresen (2024).
5 Das TPACK-Modell (Kurzform für Technological Pedagogical Content Knowledge) zeigt in orientierungsstiftender Funktion, welche Wissensbereiche bei dem Einbezug von Technologien in den Schulunterricht beteiligt sind. Das Modell wird im folgenden Kapitel genauer vorgestellt. Das SAMR-Modell (Kurzform für Substitution, Augmentation, Modifocation und Redefinition) ist ein Arbeitsmodell, auf das sich Klaus Zierer (2018, 73 f.) bezieht. Es stammt von C. Punentedura und beschreibt vier Ebenen des Einbezugs von Technik im Schulunterricht: 1. Substitution (Ersetzung: Technik ist direkter Ersatz für Arbeitsmittel, es erfolgt keine funktionale Änderung), 2. Augmentation (Erweiterung: Technik ist ein direkter Ersatz des Arbeitsmittels, dabei erfolgt eine funktionale Verbesserung), 3. Modification (Änderung: Technik ermöglicht eine beachtliche Neugestaltung von Aufgaben) und 4. Redefinition (Neubelegung: Technik ermöglicht die Erstellung neuartiger Aufgaben, die bisher unvorstellbar waren). Ein Lerneffekt tritt im Vergleich mit traditionellen Medien vor allem auf der dritten und vierten Ebene ein: Je besser es Lehrpersonen gelingt, „neue Medien so einzusetzen, dass sie bisherige Aufgaben im Hinblick auf Anforderungsniveau und Kommunikation ändern und neu belegen, desto größer wird der Einfluss auf die Lernleistung“ (Zierer 2018, 75). Das Primat der Pädagogik / Primat des Pädagogischen bezeichnet im Hinblick auf den Einsatz von Technik im Schulunterricht den Grundsatz, dass der Einbezug neuer digitaler Medien und Technologien in den Schulunterricht nicht ohne didaktisches und pädagogisches Fundament erfolgen sollte. Dem Grundsatz ‘Pädagogik vor Technik’ folgend soll eine neue Technologie nicht unmittelbar nach ihrem Erscheinen in den Schulunterricht integriert werden, sondern nur dann, wenn sie dazu beiträgt, den Erziehungs- und Bildungsauftrag besser zu erfüllen.
6 Darauf wird bereits in der Seminarbeschreibung hingewiesen, damit die Studierenden noch vor der Anmeldephase wissen, dass für die Teilnahme ein Laptop benötigt wird und, falls nötig, Leihgeräte organisiert werden können. Alternativ kann das Seminar auch in einem Computerraum der Universität durchgeführt werden. Dadurch wird ausgeschlossen, dass Studierende ohne eigenes Gerät nicht am Seminar teilnehmen. Gleichzeitig entfallen die Vorteile, die durch die Arbeit am eigenen Gerät entstehen.
7 Moretti zufolge fokussiert die Literaturwissenschaft weniger als 1 % der gesamten literarischen Produktion und beschäftigt sich vorrangig mit immer denselben Texten und Autor:innen. Hermann und Lauer beschreiben diesen vergleichsweise kleinen Teil der gesamten Literaturproduktion als „die besonderen Werke“ (Herrmann & Lauer 2018, 127). Mit dem Fokus auf die wenigen bekannt gewordenen Werke und Autor:innen ist die Forschung auf die absoluten Ausnahmeerscheinungen ausgerichtet und blendet einen Großteil aller literarischen Werke aus. Herrmann und Lauer beschreiben den großen Anteil der unberücksichtigten Werke als das eigentlich Typische der Literatur (Herrmann & Lauer 2018, 127), Moretti in Anlehnung an Margaret Cohen (1999, 23) als the great unread (Moretti 2000).
8 Für die adäquate Auswahl einer Stichprobe eignet sich der Beitrag von Christof Schöch (2017). Darin werden drei Strategien (repräsentative Stichprobe, balancierte Sammlung oder opportunistische Auswahl) zur Zusammenstellung einer Textsammlung, bei Schöch als Datensatz bezeichnet, vorgestellt und (statistische) Herausforderungen erläutert.
9 Das Format Prompt-a-thon wurde an der Universität Hamburg entwickelt und ist angelehnt an den in der Informatik gängigen Hack-a-thon, bei dem kollaborativ und in einer vorgegebenen Zeit an einer Lösung zu einer Herausforderung oder einer Idee gearbeitet wird. Der Prompt-a-thon ist also eine niedrigschwellige, praktische Einführung in der Arbeit mit gKI. Nach einer kurzen theoretischen Einführung arbeiten die Teilnehmenden kollaborativ an sogenannten Challenges / Herausforderungen. Dabei handelt es sich um vordefinierte spezifische Aufgaben, die in den Kleingruppen mithilfe von gKI gelöst werden. Die Universität Hamburg ermöglicht Mitarbeitenden und Studierenden seit April 2024 durch die universitätseigenen KI UHHGPT einen datenschutzkonformen Zugang zu ChatGPT.